Everyone's racing to build the next AI agent. But most teams skip the foundational question: How will you actually run it safely, observe it meaningfully, and evolve it without fear?
An agent isn't just a clever script that invokes an LLM. It's a living system. And unless you've laid the groundwork—observability, evals, rollout control, it's going to rot fast in production, or worse, cause silent(ha!) damage.
Let's walk through what you should build before you ship your first agent.
If you want a headstart on an open-source agent SDK, here's ours.
1. Build an Eval-First Pipeline
Agents aren't static models—they're evolving behaviors. That means you need continuous evaluation, not just fine-tuning benchmarks.
Key Requirements
- Continuous evaluation, not just fine-tuning benchmarks
- Structured traces, intent detection, and task outcome metrics
- Store replayable sessions for regression testing
Structured Logging and Observability
Langfuse or OpenTelemetry for comprehensive tracing
StarOps Tip
Ship agents inside a workflow that includes eval steps as gates. You shouldn't just "deploy and pray"—you should "deploy and measure."
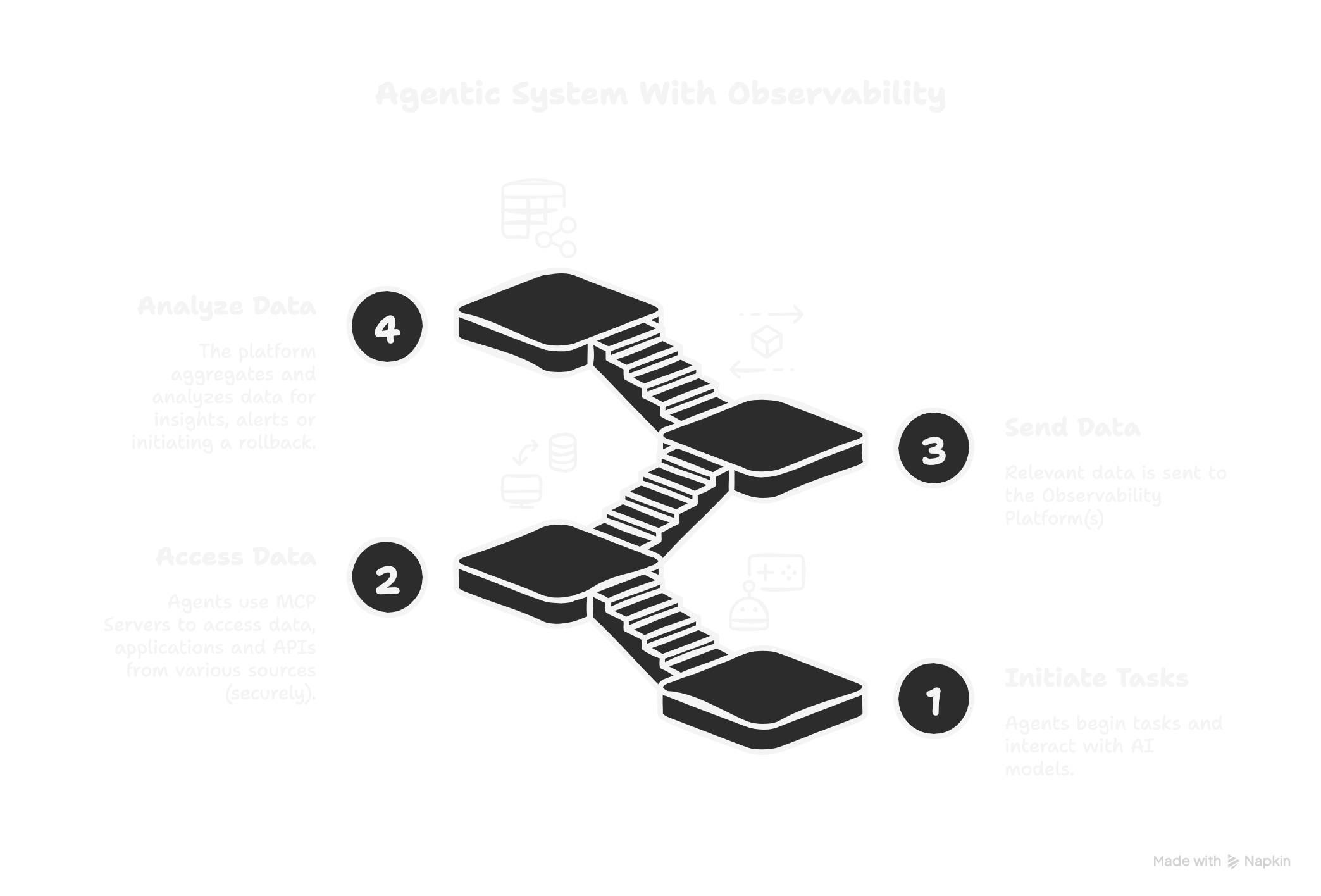
2. Observability That Goes Beyond Logs
Don't wait until your agent is hallucinating in production to figure out what went wrong.
Build In These Capabilities
Prompt + Context Tracking
Track per request with full context
Cost Profiling
Across providers (per-tool token usage)
User Feedback Hooks
Baked into your UI or CLI
Structured JSON Logging
Include model, system prompt, user input, and chain of tools used—tagged with trace IDs and session metadata
3. Permission-aware Rollouts with Canary & Blue/Green
Your agent will need elevated permissions eventually—access to real data, payment APIs, internal tools. That's not a flag you flip. It's a ladder you climb.
Progression Pattern
Sandbox Mode
Agent runs in dry-run mode, logs but doesn't act
Canary Deployments
Limited users, low-stakes tasks
Blue/Green Deployments
Shift traffic to newer version with rollback baked in
Full Rollout
Deployed to all users with continuous monitoring
StarOps makes this easy by defining environments with scoped IAM policies and enabling gradual promotion across stages (e.g., from dev → stage → prod).
4. CI/CD with Guardrails and Hot Reloads
Fast iteration only works if you're not redeploying your entire cluster for every tweak.
Best Practices
- Use ArgoCD for declarative GitOps with environment drift detection
- Incorporate eval checks into the pipeline as test gates
- Define rollback plans if regression is detected post-deploy
Hot-Reloadable Techniques
- Mount model files via S3 or blob volumes + notify agents on change
- Use feature flags to control model or prompt versions
- Externalize model providers behind a dynamic router (e.g. proxy API)
StarOps integrates with ArgoCD, making it easy to trigger evaluations and manage staged rollouts based on Git changes, not just script pushes.
5. Agent Tools & External APIs: Trust Nothing by Default
If your agent uses MCP (Model Context Protocols) Servers, YouTube APIs, browser wrappers, or internal APIs, you're now in cross-domain territory.
Security Must-Haves
Trace Identifiers
Every request should carry a trace identifier that survives across external tool boundaries
Fine-Grained Access
Use fine-grained service accounts, not global credentials
Secure Actions
Secure agent actions using scoped OAuth tokens, short-lived API keys, or OPA policies
Zero-Trust Approach
Treat every tool like a potential breach point — zero-trust applies to agents too
Example: If your agent books calendar invites via Google Calendar, ensure the RBAC prevents it from deleting meetings or accessing other user scopes.
The Bottom Line
An agent without infrastructure is an incident waiting to happen.
If you're serious about deploying agents that evolve safely over time, you need:
That's exactly what we're building at StarOps, a platform where GenAI agents and other cloud-native artifacts can thrive, not just survive.
Before you build your agent, build the engine to run it well. That's what StarOps is for.