Hot Swap Your Models: Designing for the AI UX That Learns With You
The Problem With One-Size-Fits-All Agents
AI tools today too often assume one model, one chain, one path. You hit a button, invoke an agent, and get a response. Maybe it works. Maybe you retry. Maybe you leave. That rigidity is holding us back. Because users are nuanced. One person wants speed over specificity. The next wants citations and depth. So why are we giving everyone the same agent?
Enter hot swapping: the ability to dynamically switch or parallelize models, prompts, or even full agent chains, live, based on context. It’s not just clever routing. It’s an architectural choice that says: our users are varied, so our system must be too.
What is Hot Swapping in AI?
Borrowed from hardware ops—where you replace a drive without shutting the machine down—hot swapping in AI is a Formula 1 pit stop for your agents. The system dynamically swaps or spins up the right model, prompt strategy, or even an entire agent graph in the middle of a conversation—without breaking flow.
Claude for creative ideation, GPT‑4 for precise parsing—pick the right engine per turn.
Chain‑of‑thought, ReAct, few‑shot vs. zero‑shot—adapt reasoning style to context.
Swap full agent structures based on the detected task (research, planning, execution).
Turn RAG on/off, enable web search, or route to code execution when needed.
Dial safety and grounding levels up or down based on risk profile and domain.
Example: You start brainstorming a tagline, then paste a policy doc. The system pivots from a fast, expressive model to a grounded RAG chain—no dropdowns, no friction.
Done right, this happens in real time. No toggles. No “advanced settings.” The system anticipates and adapts.
Segmenting User Requests: Not All Prompts Are Equal
Most AI interfaces treat all prompts the same. But in production usage, you quickly learn that requests segment naturally:
Vague, speculative, preference-driven
Needs tight grounding and verifiable references
Expects action, structure, and determinism
- Pick the lowest common denominator (bland answers)
- Blow costs trying to make one model do everything
Hot swapping allows you to match intent to method:
Route to a cheap, expressive model.
Swap in a slower, grounded RAG agent.
Users don’t need to know the internals. But they feel the difference.
Parallel Agents: Let Them Compete or Collaborate
Here’s where it gets really interesting.
Instead of serial chains, consider parallel chains:
- One agent uses a standard LLM
- One uses your internal documentation via retrieval
- One runs a chain-of-thought tree
Now you have:
- Multiple candidates
- Different reasoning paths
- Redundancy for safety or clarity
You can:
- Present all answers to the user (like a multi-model assistant)
- Score and pick the best one
- Blend outputs if your UX supports it
This strategy is inspired by search engine result ranking, ensemble learning, and even human decision-making (we often ask multiple people for input, then synthesize).
Example: A user asks, “What are the regulatory risks of AI in healthcare?”
- Claude provides a high-level summary
- GPT-4 gives granular legal nuance
- Your in-house agent pulls quotes from FDA docs
Now your user is getting a panel of perspectives.
Measuring What Matters: UX Metrics for AI Agents
Traditional metrics like latency or token count don’t tell you much about user success. Instead, think:
- Time to Satisfaction: how long from question to "yes, that's what I needed"
- Cognitive Load: is the user thinking about their task, or your interface?
- Retry Rate: are they re-asking the same thing with different words?
- Win Over Time: is the system getting better for this user over repeated sessions?
These are product questions, not just infra ones. But they depend on infrastructure flexibility.
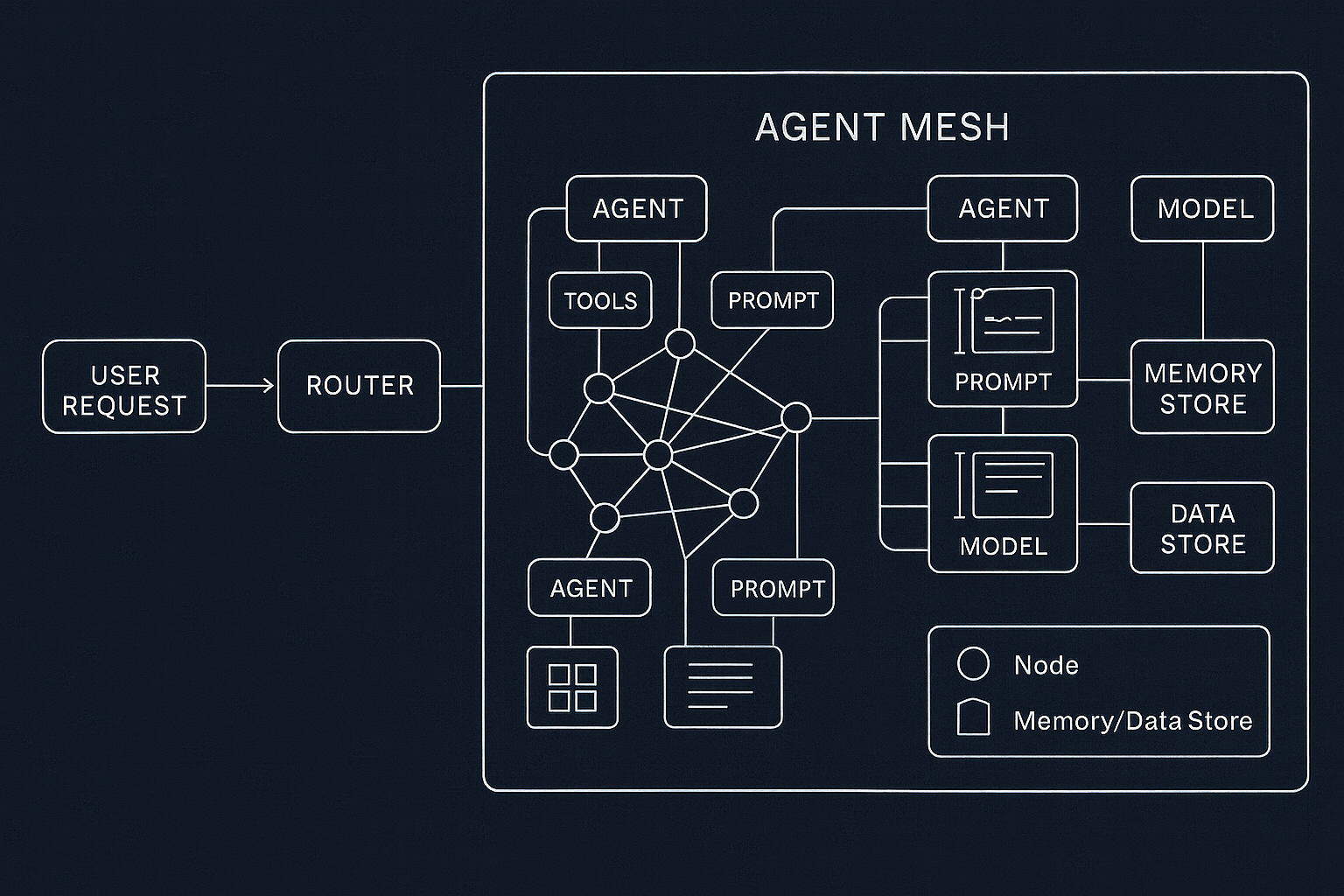
Infra Tips: Building an Agent Mesh with Kubernetes
If your platform can’t support parallelism or dynamic routing, you’re stuck at the UX layer. Design for flexibility with these building blocks:
Treat agents as pluggable services. Template with Helm or Kustomize for variations.
Route to the right pod via Istio/Linkerd or a lightweight HTTP router.
Classify intent and select the right model/agent at the gateway.
Tag requests by agent/model/path. Export to Prometheus/Grafana or OpenTelemetry.
Fail gracefully with circuit breakers and alternate agents when errors occur.
Closing: From Static Pipelines to Adaptive Agents
Hot swapping isn’t just a UX trick. It’s a mindset shift. AI systems that adapt in real time to context, user behavior, and task type feel magical. But behind that magic is a lot of architectural design:
- Smart prompt routing
- Dynamic container orchestration
- Observability + feedback loops
The future isn’t "the best model wins." It’s "the best blend of agents for this user, right now, wins." Build for that.
One More Thing: Don’t Reinvent Infra. Focus on What Makes You Special
Companies building adaptive agent platforms shouldn’t waste time rebuilding infrastructure primitives. Your value is in the domain expertise, the business logic, the specialized tuning that makes your agents useful.
For everything else—cluster orchestration, cost tracking, observability, model deployment; use tools that are purpose-built for AI infra.
That’s why we built StarOps. It’s a modern platform engineering engine that helps you deploy and operate agents, models, and workflows with Kubernetes-native primitives and battle-tested cloud integrations. You focus on great user experiences. We’ll handle the ops.
Stay flexible. Stay fast. Stay focused on what makes your system smart.